The Shakespeare and Company Project is based on the Sylvia Beach papers at Princeton University Library. Logbooks and lending library cards trace members’ engagement with Beach’s famous lending library in Paris. Members included literary luminaries Gertrude Stein, James Joyce, Ernest Hemingway, and Simone de Beauvoir, as well as students, businessmen, and French girls with English governesses. A significant part of the project data consists of events: memberships, renewals, reimbursements, borrowed books, purchased books, etc. Yet, due to the fragmentary and handwritten nature of these sources, the dates aren’t always easy to manage with code. Working on the project required managing imprecise data with precise code.
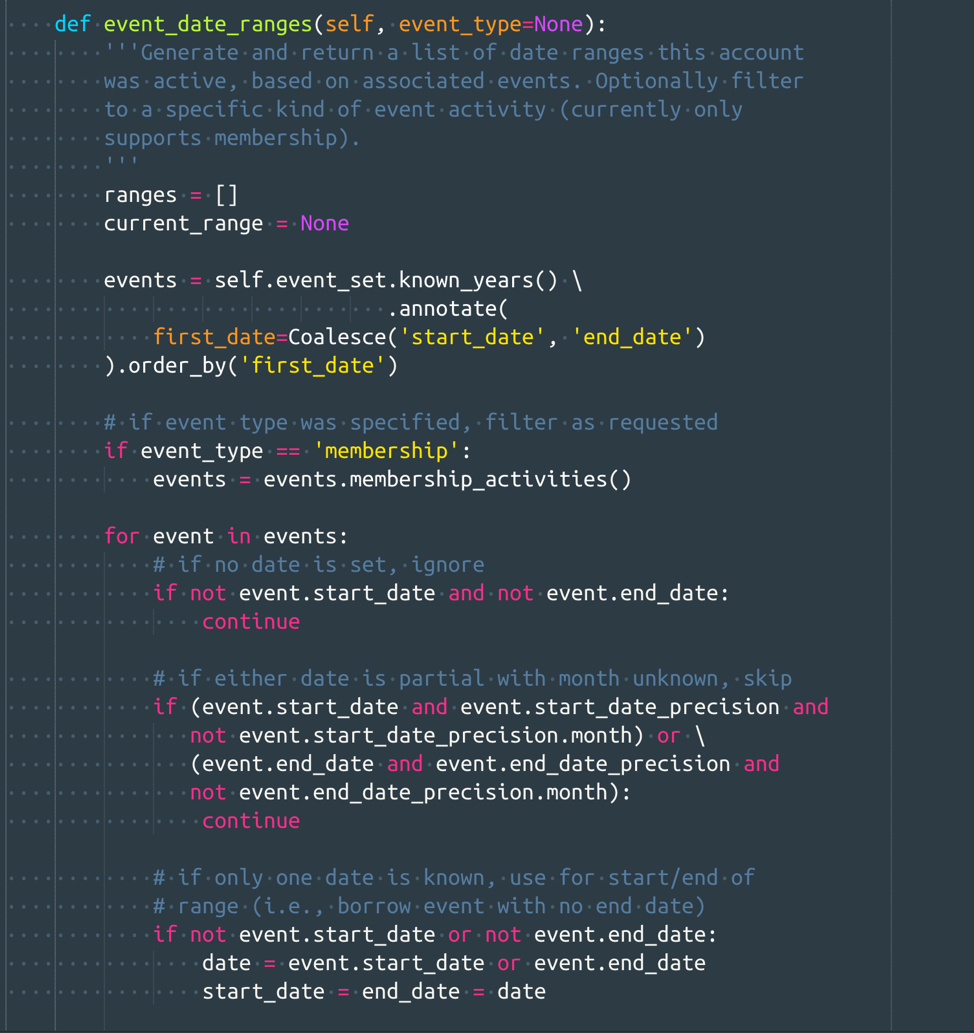
Let’s walk through how we tackled one aspect of this problem. The event_date_ranges method previewed above (view the full method on GitHub) aggregates all events for a library member into a timeline of known activity. The resulting list of date ranges is the basis for visualizing a member’s engagement with the library. This method loops through all the events for a member, sorted by date, and collects them into groups of date ranges. If an event starts within or up to one day after the current date range, it is included and the range is extended, if needed; if not, that range is closed and a new range is started. For Simone de Beauvoir, who was active in 1937 and 1940, the results look roughly like this:
[[1937-04-07), 1937-05-03)], [1940-07-25, 1940-12-31]]
You would probably expect a member’s borrowing activity to occur within the dates they were a member—but, due to missing logbooks and the oddities of human behavior, that’s not always the case.
The code has to handle one-day events, like buying a book or closing out an account, as well as longer-duration activities, like a membership or borrowing a book. In addition, because these are historical records that were kept by hand, and not all preserved, we have to handle a variety of unusual dates. There are date ranges with a start but no end, and in some cases, end dates with no start; the code here treats those as a single date.
Project data also includes partial information—some lending library cards document borrowing activity with the month and day noted but no year. In this method, I exclude those partially known dates entirely; known_years() on line 95 filters out events with an unknown year, and lines 109-114 filter out events with unknown months. We can use dates with less precision elsewhere, like filtering members by years they were active, but not when we need the precision to plot dates on a timeline.

How can we think about the relationship between messy historical sources and precise code as developers? It helps to think of coding as writing. I like to think of software in terms of audience, with the machine that will run the software as the primary audience. This is why programming languages are so particular: we’re communicating with a very literal-minded entity with a circumscribed vocabulary. Unlike a human reader, who will make leaps of understanding or see mistakes and understand what you meant, the computer refuses to read what you write if you get the syntax wrong. In fact, it’s more complicated than that—high-level programming languages are compiled into machine code, so when we write code, we’re really communicating with a digital interpreter that translates what we write into the limited, structured vocabulary of the machine.
And yet a lot of the phrases we use to describe writing code are similar to those we use to describe writing. We talk about code being “readable,” and some programming languages are known for being more readable than others. We “refactor” code, which is a kind of revision—restructuring or simplifying the code to make it more efficient or readable while preserving the original logic. There’s a practice called “code review,” akin to editing. We talk about whether a piece of code is “elegant,” and, as with writing, shorter code is often better, but also harder to write. (In fact, re-examining my own code to write the above description helped me see things that could be simplified.)
As a software developer—unlike a literary writer—the better I do my job the less likely it is that anyone will read my code, since we usually only go back to old code to find and fix problems. However, the tools of collaborative writing and editing are still powerful ones for thinking about and writing code, which is in turn expanding and transforming the ways we write and communicate with each other.
To read more of my perspective on the parallels between writing and development, see Coding is Writing.