The following is content associated with a poster presentation for Open Repositories 2016.
Why create Disk Images?#
Born-digital material is archival material, not a surrogate for archival material (in the way that a digitized copy of a handwritten letter would be, for example). As such, the archival principles of provenance, authenticity, and context apply to born-digital materials.
- PROVENANCE: Documenting the history and context of an object
- AUTHENTICITY: Establishing that the object is indeed what we say it is
- CONTEXT: Representing the relationships between objects and the way in which they were created and used
Borrowing from techniques used in digital forensics, many archivists choose to capture forensic disk images of born-digital material as a way of adhering to these three important principles. This creates an exact replica of the digital artifact at the bitstream level, thereby ensuring no inadvertent change or loss of data during transfer. The creation of checksums can then be used to verify that the capture of a disk image has been successful, which helps to authenticate the data. Furthermore, disk imaging preserves filesystem metadata and, in cases where software is stored on the disk in question, associated representation information that can help identify and render files. Taken together, these benefits help archivists establish and document the provenance, authenticity, and context of born-digital archival material.
Disk Image ingest workflow#
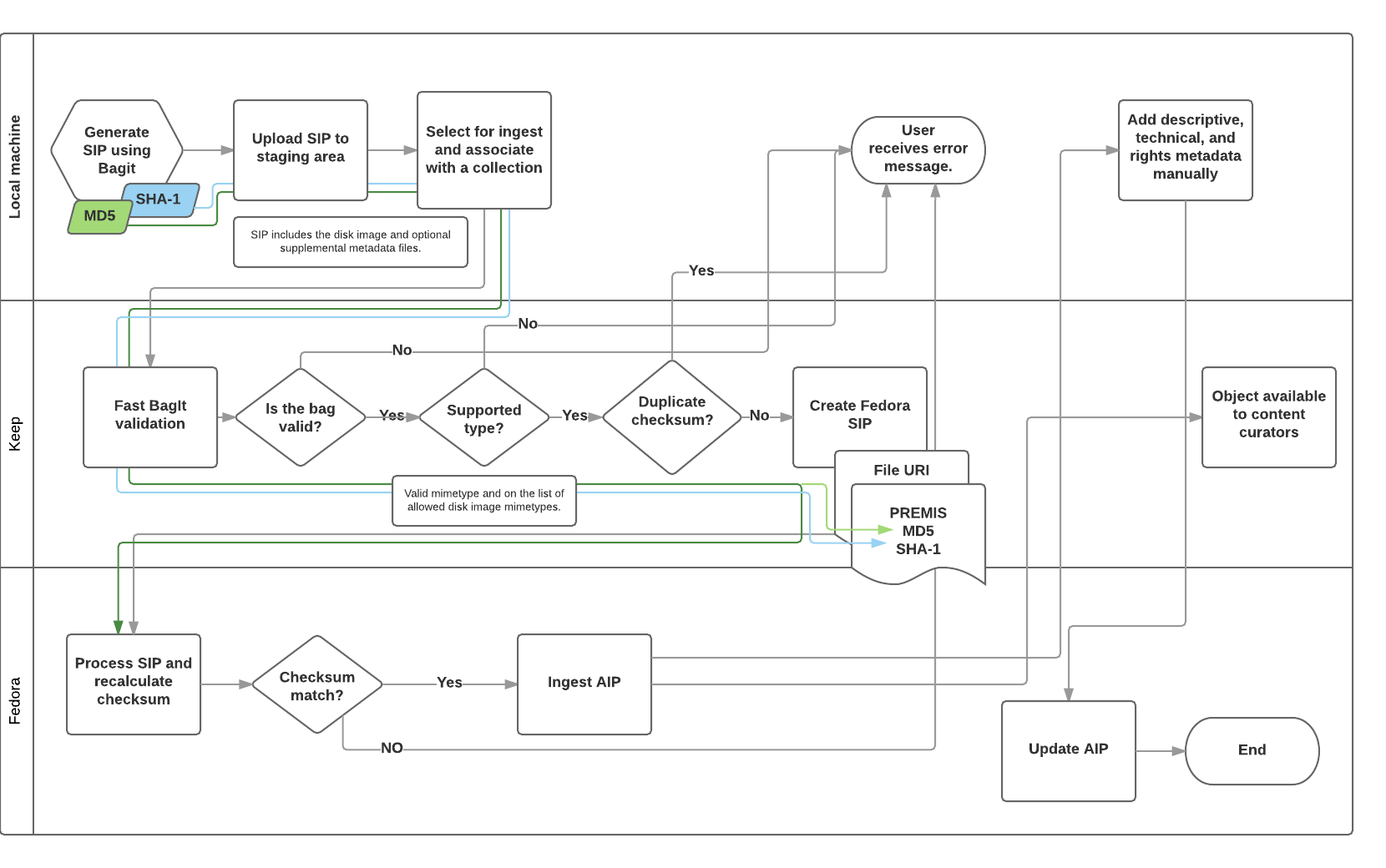
Why Use BagIt?#
- Acts as a protective wrapper during transfer.
- Validation of entire package and contents.
- Maintains provenance of the SIP (object + metadata that tracks chain of custody)
- Checksum manifest, which supports multiple algorithms (e.g. both MD5 and SHA-1).
The Landscape at Emory#
436 disk images, 1.2 TB total (includes migrated content)
Average 2.8 GB, largest 298GB (see charts below for more detail)
E01, ISO, IMG, DD, TAR*{.fn}, AFF†{.fn}, AD1†{.fn}
†: migrated format
5% of all Rose Library manuscript collections contain some form of born digital content.
| Acquired Pre-2000 | 1% |
| Acquired 2000-2010 | 10% |
| Acquired 2010-2016 | 13% |
* Why Create TAR Files?#
The capture of forensic disk images at Emory is not always possible. In conversations with donors, Rose Library archivists aim to be transparent about transfer methods and the fact that forensic disk imaging captures a complete replica of data can cause some anxiety for donors. In these instances, we capture specific files and directories using the TAR utility.
Other Benefits of Disk Images#
- Packages born-digital data, so that it can be safely moved without the risk of alteration.
- Removes the need to rely on aging and often obsolete media.
- Provides the means to create a complete copy of the data, for preservation purposes, without requiring that I interpret the data—this can then be done at my leisure as and when I have the resources and tools.
- Provides greater ease of emulation as an access point.
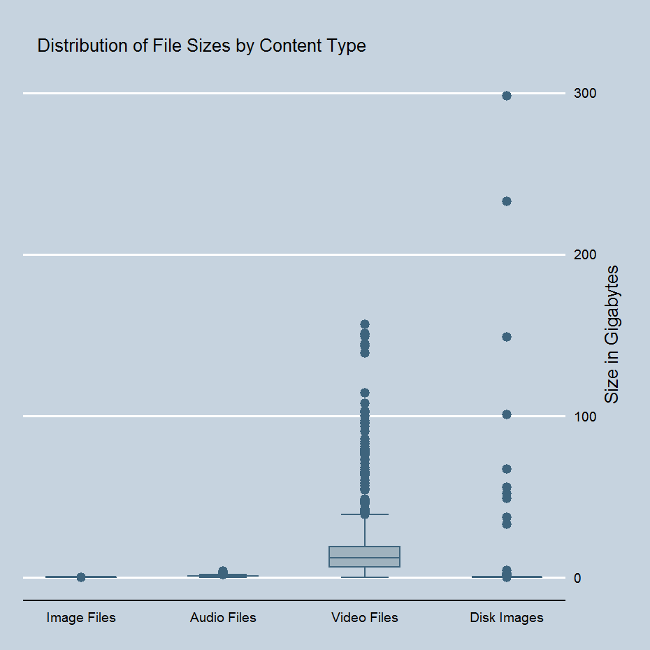
File Size Distribution#
One of the complexities we had to deal with to support disk image ingest was the wide range of file sizes. The majority of our disk images are quite small, but a handful of them are quite large, and disk images include the single largest file currently in our repository.
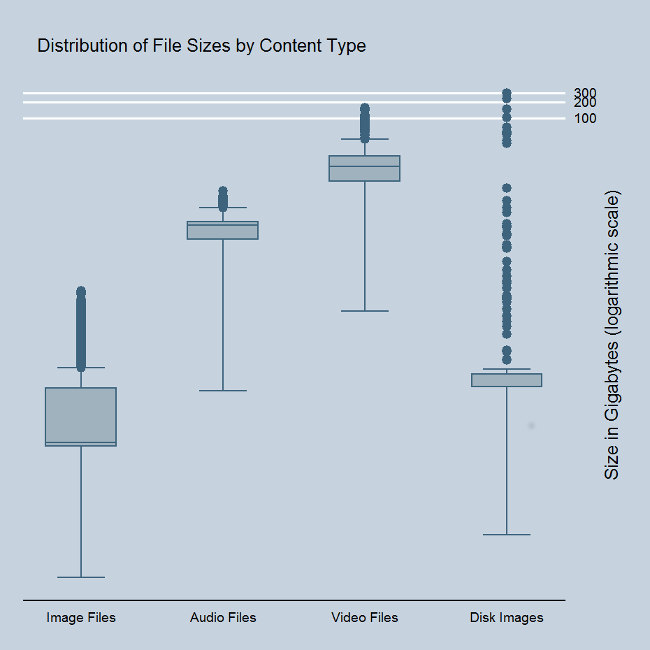
The difference in scale of file sizes makes it difficult to compare images, audio, video, and disk image content. The linear box plot makes it clear how many outer values we have for disk images, and how they are fewer but much larger than video content. The logarthmic scale makes it easier to compare the relative sizes of the smaller range of files, but makes it harder to grasp the true difference in scale at the higher end of the sizes.
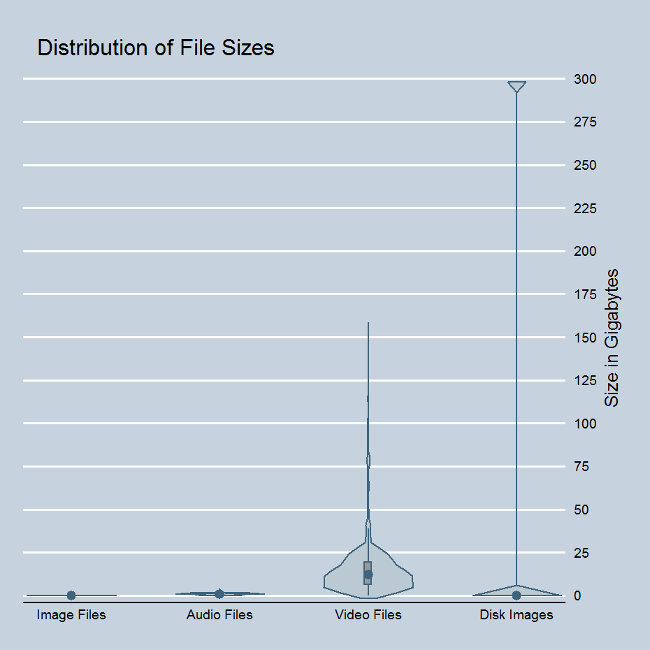
The violin plot is an alternate way of visualizing the same data, and it also makes it quite clear that the distribution of the disk image sizes are quite different from the other content we typically handle.
The presence of very large files, even though they are not the norm, meant we had to design a workflow that could handle them. We addressed time out issues in the ingest process by using BagIt to generate MD5 and SHA-1 checksums ahead of time, using fast BagIt validation at the application level, storing both checksums in the PREMIS metadata and passing the MD5 checksum on to Fedora for verification. That way, the checksum is only recalculated once during the ingest process (since checksumming a large file takes a correspondingly long time). We also use file URIs and a shared network drive space accessible to staff curators, the web application managing ingest, and Fedora in order to transfer the content as efficiently as possible.
Tools and Resources#
- FTKImager, used to capture disk images; CLI version used to migrate AFF content to E01
- BitCurator, used to capture disk images; includes BagIt
- PREMIS, for object technical metadata and history/provenance
- BagIt; bagit-python
Credits#
Disk Image workflow designed and refined by Dorothy Waugh, Elizabeth Russey Roke, and Rebecca Sutton Koeser; software implementation in our curation application, “The Keep” by Rebecca Sutton Koeser; python-bagit update to support SHA-1 and multiple checksum types in the manifest by Rebecca Sutton Koeser.
Thanks to Rob O’Reilly for assistance with statistical analysis and advice on the file sizes and for generating the box and violin plot images.

