This session included three very different approaches to visualizing aspects of English language and literature - a visualization tool for poetry, surprisingly beautiful tree-maps of the history of the English language, and vocabulary trends in English literature over the 18th and 19th Century.
Myopia: A Visualization Tool in Support of Close reading#
presented by Laura Mandell (view abstract, video of the presentation)
“Myopia” is a poetry visualization tool designed to support close reading, created by collaboration with a Computer Science graduate student, professors in English and Pyschology, a visual designer, and the like. The team is looking at experimental visualizations of poetry using the Poetics archive, and also making use of some of the work done in relation to the “For Better For Verse” metric poetry teaching site, where students encode poetic scansion in TEI.
Myopia is a software tool written in Python with a visual interface for examining poetry; for instance, it can display metrical feet, and show or hide the text. When Mandell demonstrated some of these features, it reminded me of Jerome McGann’s notion of “deformative interpretations” and “performative interpretations” (his examples were things like isolating nouns or verbs and hiding the rest of the text). Laura Mandell also talked about tropological encoding; she used her own scheme, which she developed for this tool; among other things, her scheme includes the “seven types of ambiguity” (which sounds like it should be the name of a band or a poem or something). In the process, this group ran into the same restrictions of the unitary hierarchy of TEI which has been mentioned in other sessions– what do you with overlapping items like metaphor, assonance, etc? It doesn’t make much sense for one to be contained by the other; so they ended up splitting out the text and creating multiple versions of the same poem to encode different aspects of the poetry.
I’m very interested in experimental ideas for visualizing poetry, but I’m not completely sold on this project; I think part of that is because I don’t understand what the point is– whether this is intended as a teaching tool, or an exploratory one where students or readers interact with texts that have already been richly encoded, or perhaps something else (and when Laura Mandell was asked about this after her presentation, she didn’t seem to have much of an answer). In her talk, Mandell made reference to the fact that close reading is a slow process, but it’s hard to think that this approach is “saving time” in any real way, when you consider the amount of time and effort into building this system, deciding on encoding approaches, and then doing the actual encoding. I think even if you only count the encoding step and assume the system already exists, this is still probably a much slower process than normal close reading, and it’s not clear to me that there is a huge benefit or much difference in the eventual outcome. And it’s probably also worth asking whether saving time is something we value when it comes to reading literature; isn’t part of the point of close reading is that it requires the reader to spend time with the text?
The other problem I have with this tool (and other poetry visualizations I saw during the conference) is that I don’t think the visual display it provides is representative of the text; poetry has a visual aesthetic, and this kind of interface would seem to homogenize all poetry with the same “colors” for tropes and meter, whether those colors suit the beauty or roughness of the text. I had an interesting conversation with Kate Singer, who presented a poster with a similar approach, using TEI markup of poetry as a pedagogical tool; her abstract includes images of the markup and the poems (again with bright, multi-colored text; now that I have seen this multiple places, I find myself wondering if the students came up with that particular visualization of the tropes they encoded, or if it was just a convenient display method they were provided with). Kate disagreed with me about the value of Myopia and Laura Mandell’s work; the one argument Kate made that I found rather compelling is that Mandell’s work to understand poetry to the depth she needed to (Mandell commented in her talk that it was a difficult task that took all her abilities) in order to encode the texts for this project may be the most valuable thing to come out of it.
As a side-note, one of the tangentially related thoughts that crosses my mind when I see projects like these is: what it would take to use scansion-tagged poetry, along with existing resources for the pronunciation and sound of words, as a sort of training set for automated detection of meter in poetry?
Patchworks and Field Boundaries: Visualizing the History of English#
Marc Alexander / @marcgalexander (view abstract, video of presentation)

This presentation was one of the best of the conference - engaging, interesting, relevant, and hinting at lots of great future work to be done; I highly recommend that you take a look at the video or at least flip through his slides (see the #dh2012 twitter stream to see the glowing accolades if you don’t believe me; Alexander won the conference Fortier prize for this talk).
Alexander is working with a dataset from the Historical Thesaurus of the OED, a fine-grained, detailed, hierarchical thesaurus that was pain-stakingly organized and collected over decades; in this talk, he presented treemap visualizations with light and dark gradations of color to display the age of word use in different times. The full visualization for modern English makes it clear that there were sections of marked, rapid vocabulary growth; comparing visualizations from different time periods shows a lack of evidence for similar vocabulary growth, and can also be used to show the relative vocabulary size of those different periods (although it’s worth noting that the Old English vocabulary is probably not very representative, since we only have the language that survived via heroic and religious texts).

Alexander also made reference to his Mapping Metaphor project, and demonstrated with a few examples that metaphors always cross the major category bounds of the language– which we should probably expect, since metaphor is used to compare disparate things or ideas.
When asked about the dataset, Marc Alexander replied that is not currently available, but he hopes that it will be soon, likely with a tiered license (hopefully free for non-commercial use), and that the released dataset should also include the OED, which would allow graphing etymologies also. One commenter suggested he might filter his visualizations by common usage, but Alexander answered that there isn’t any data available for this. I find myself wondering if there are any datasets like this for other languages, as it seems that comparing English with other languages could be quite enlightening, e.g. for relative vocabulary size or periods and areas of marked growth.
The Differentiation of Genres in 18th and 19th Century English Literature#
Ted Underwood (view abstract, video of the presentation)
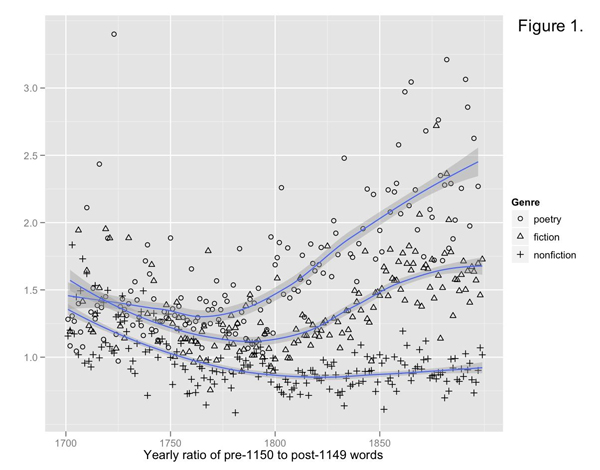
According to Ted Underwood, the general strategy of corpus comparison can be hard to interpret, and it is often easier to interpret a series of comparisons over time. So, working with a metric of the ratio of pre- and post- 1150 words, Underwood and his collaborators graphed the language use across multiple categories, and discovered a noticeable change that parallels the emergence of literature as a category. The graph for poetry shows the strongest differentiation - providing some basis for the claims of Wordsworth and the other Romantic poets about using the spoken language of the middle and lower classes rather than the learned, erudite, Latinate language more commonly in use previously. Underwood also noted an increase in the terminology of personal experience, suggesting that the informal language may also be driven by certain thematic concerns relating to subjectivity and personal experience.